For a true unique primary key in a distributed environment, AUTOINC does not work well. So I always recommended to use either an AUTOINC combined with some kind of SiteId, or to use a GUID (global unique identifier). Prior to ADS12, a GUID had to be stored in a CHAR field. This value had to be generated in the application, or – since version 8.1 – by calling a scalar function named NEWIDSTRING([format]). Depending on the format parameter, this function returned a 22-byte, 24-byte, or 32-byte formatted string. As an example, following SQL statement returns the GUID formatted as hexadecimal string with curly braces {xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx}:
SELECT newidstring(C) FROM SYSTEM.IOTA;
In version 12 a true native GUID data type was added. This field type is stored in a 16-byte RAW format, a new scalar function generates and returns this data structure:
SELECT newid() FROM SYSTEM.IOTA;
Let’s put this into a table:
CREATE TABLE employees(id GUID, firstname CICHAR(30), lastname CICHAR(30), branch CICHAR(30)) IN DATABASE; INSERT INTO employees(id,firstname,lastname,branch) VALUES (newid(),'Homer','Simpson','Sales'); SELECT * FROM employees;
Using this field type with an older client (e.g. Data Architect V11.1) will result in an error:
poQuery: Unknown field type (29) encountered.
In order to work with older clients, a workaround is required: The GUID has to be generated on server side and a string representation has to be returned to the client. Let’s start with the server side GUID generation. Easiest to implement this as a trigger:
CREATE TRIGGER trig_ins ON employees INSTEAD OF INSERT BEGIN UPDATE __new SET ID=newid() WHERE ID IS NULL; INSERT INTO employees SELECT * FROM __new; END;
This reduces the INSERT statement to following:
INSERT INTO employees(firstname,lastname,branch) VALUES ('Marge','Simpson','Sales');
But still: reading this field in older clients will result in an error. So you need to cast it. This could be done either in the SQL statements, or you use a view:
CREATE VIEW vwemployees AS SELECT CAST(id as SQL_CHAR), firstname,lastname,branch FROM employees; SELECT * FROM vwemployees;
But now return to ADS12. New in this version is also the ability for multi-row INSERTS. Instead of calling an INSERT statement multiple times, you can simply add additional VALUES vectors to a single INSERT statement. Let’s add some more records:
INSERT INTO employees(firstname,lastname,branch) VALUES
('Bart','Simpson','R&D'),
('Lisa','Simpson','R&D'),
('Maggie','Simpson','QM');
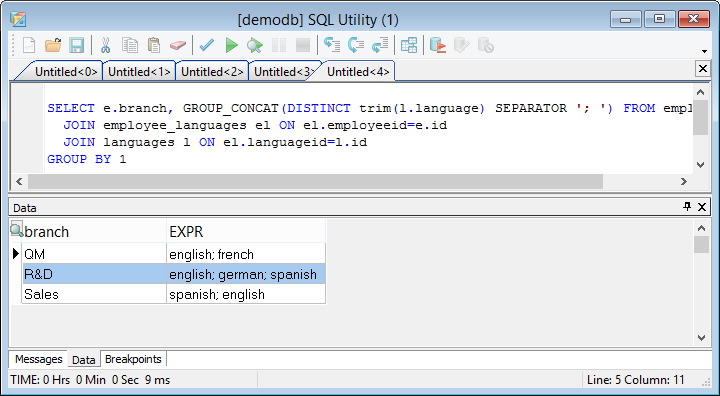
Having these records in the table, we can query all branches and the members that belong to the specific branch:
SELECT branch, GROUP_CONCAT(trim(firstname)+' '+trim(lastname) SEPARATOR '; ') FROM employees GROUP BY 1;
btw: SQL statements are executed by the server, so this statements also works in older clients against ADS server 12.
For a further example I want to add languages. The language table contains all the languages spoken and a link table named employee_languages links the languages to the employees:
CREATE TABLE languages(id GUID, language CICHAR(20)); INSERT INTO languages VALUES (newid(),'english'), (newid(),'spanish'), (newid(),'german'), (newid(),'french'); CREATE TABLE employee_languages(id GUID, employeeID GUID, languageID GUID);
Let’s add some records:
DECLARE @l GUID;
-- english for all
@l=(SELECT id FROM languages WHERE language LIKE 'english');
INSERT INTO employee_languages
SELECT newid(), id, @l FROM employees;
-- spanish for Homer, Marge and Lisa
@l=(SELECT id FROM languages WHERE language LIKE 'spanish');
INSERT INTO employee_languages
SELECT newid(), id, @l FROM employees WHERE firstname in ('Homer','Marge','Lisa');
-- german for Bart and Lisa
@l=(SELECT id FROM languages WHERE language LIKE 'german');
INSERT INTO employee_languages
SELECT newid(), id, @l FROM employees WHERE firstname in ('Bart','Lisa');
-- french for Maggie
@l=(SELECT id FROM languages WHERE language LIKE 'french');
INSERT INTO employee_languages
SELECT newid(), id, @l FROM employees WHERE firstname in ('Maggie');
Getting all the languages and the employees/branches in a result set is an easy task:
SELECT l.language, e.firstname, e.branch FROM employees e JOIN employee_languages el ON el.employeeid=e.id JOIN languages l ON el.languageid=l.id
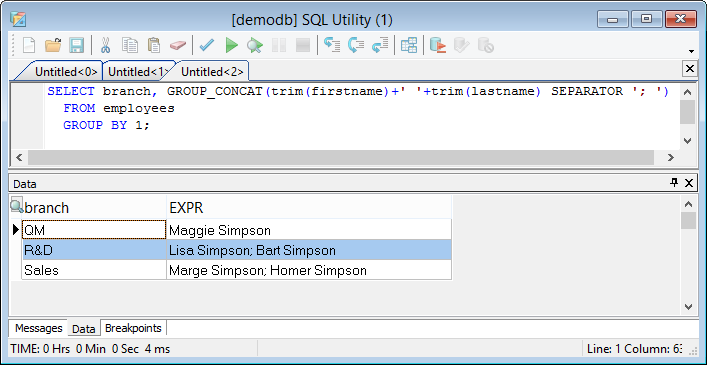
To get a list of all branches and the languages spoken in this branch requires either a SQL script/stored procedure or the newly added GROUP_CONCAT
SELECT e.branch, GROUP_CONCAT(trim(l.language) SEPARATOR '; ') FROM employees e JOIN employee_languages el ON el.employeeid=e.id JOIN languages l ON el.languageid=l.id GROUP BY 1
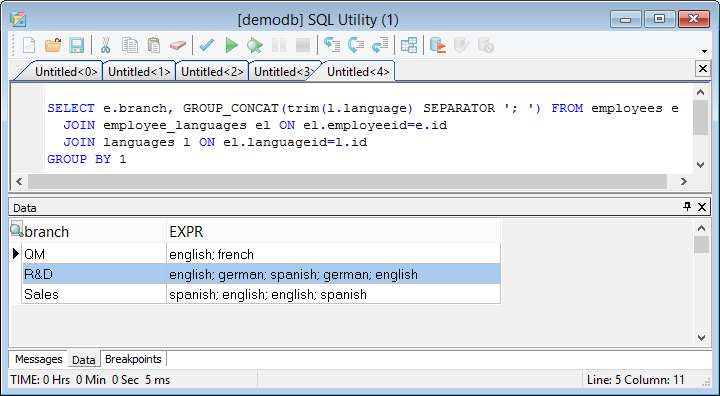
In the result set you can see the same language multiple times per branch. To avoid this, use the DISTINCT keyword
SELECT e.branch, GROUP_CONCAT(DISTINCT trim(l.language) SEPARATOR '; ') FROM employees e JOIN employee_languages el ON el.employeeid=e.id JOIN languages l ON el.languageid=l.id GROUP BY 1